The purpose of these protocols is to establish guidelines and protocols for ensuring data being uploaded into HIEv is structured in a responsible, sensible, and discoverable manner. This applies to raw data being produced by the various automated sensors operating at the WTC facility as well as manually collected raw data and researcher produced analysis/processed data. It is expected that the protocols outlined below are in place prior to upload of data into HIEv so that the potential for reuse of that data is enhanced.
The guidelines should be followed as closely as is practically possible. Of course there will be situations where the conventions cannot be followed exactly. In these situations it is expected that the researcher will still aim to produce coherent datasets that are in line with this document as much as possible. Advice on how to handle such datasets can be sought from the facility technical team and/or the HIE data manager.
(Instructions on how to upload data into HIEv can be found in the section ‘Uploading Data’ under the ‘HIEv’ menu).
Data format
- All datasets that have been manually collected should be stored in CSV (comma separated values) format, and have the extension ‘.csv’.
- Data from auto-loggers are uploaded automatically to HIEv in TOA5 format (a particular type of CSV file with four lines of header) and have the extension .dat. In some cases it might be useful to upload data in this format (for example, when data were recorded over a few days with a datalogger).
Long or wide format?
All data should be uploaded only in the so-called ‘long’ format. For example, you have measured some variable Y three times during an experiment. The data should then be like this:
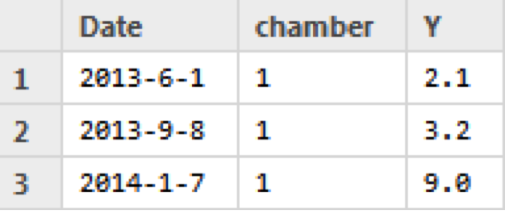
Not like this:
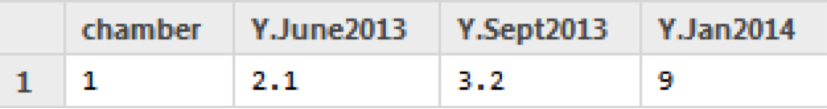
Variable Names
For variables that are not part of the ‘standard variables’, please follow some of these guidelines for good names:
- Do not include units in the column name (“Height (m)” is bad, “Height” is OK). Units will be documented in the meta-data field (see below). In special cases where you must include the units, use underscore (“diameter_cm”).
- Do not include any special characters in column names, including space. (“Tree height” is bad, “Treeheight” is OK). Special characters include /,#,$,%,(),{},[],@,~ etc. Underscores (_) , hyphens (-), and periods (.) are OK.
- Assume case-sensitivity. Try to be consistent with uppercase vs. lowercase between datasets.
Conventions for standard variables
While you have freedom in naming the columns in your dataset, we should all follow the same convention with columns that will be present in most, or all, datasets. The examples below pertain to the Whole Tree Chambers facility. Columns particular to other facilities should be discussed and agreed upon within that facility team.
- “chamber” – numbered ‘C01’ through ‘C18’ (control trees 13-18 are technically not chambers, but this variable name is consistent with WTC1). It is important that we use two digits following a character (so, ‘C01’, not ‘C1’).
- “T_treatment” – the temperature treatment, labelled ‘ambient’ or ‘elevated’ or ‘reference’ (for outside trees)
- “Water_treatment” – the drought treatment (which is to be imposed): ‘control’ or ‘drydown’ (where control refers to the watering regime prior to the dry-down).
- “Date” – the date in YYYY-MM-DD. (Note: Please be careful if you use excel to prepare the CSV file, Excel has the tendency to auto-convert dates to DD/MM/YY).
- “DateTime” – the date / time combination, in format ‘YYYY-MM-DD HH:MM:SS’ (seconds field is optional!). If you have a different format and don’t know how to convert, please seek help or otherwise make sure to document it properly in the metadata (see below).
- “comments” – any text comments to the row of data.
Collection codes
Central to the file naming convention is the so-called ‘variable collection code’. Because data files produced at WTC do not operate on a single data ‘variable’ per file, a variable collection code is used to group datasets of a similar nature,for example data on soils, or data on gas exchange of leaves. The collection codes should typically be short, but at the same time descriptive in nature. As an example a collection code currently used within the Whole Tree Chamber facility is ‘ACIGAS’ which is used to collect together a range of Leaf A-Ci curves.
Variable collection codes should be reused where possible (i.e. for similar collections of data variables). In the event that no collection exists a new term should be devised and added to the master list. Curret collection codes for each facility can be found under the ‘Naming Conventions’ menu (under ‘Data Preparation’)
File naming conventions
A key feature in organising data will be the manner in which data files are named. Although the HIEv offers a metadata query interface to its data contents, a consistent naming convention will ensure data is more easily understood and worked with when it has been downloaded from HIEv to a researcher’s desktop. It also helps eliminate file duplication, and in general is a good model on which researchers can organise their own data. File naming conventions are constructed for each facility that should allow most, if not all, data to be named in a consistent manner, and can be found under the ‘Naming Conventions’ menu
Data example
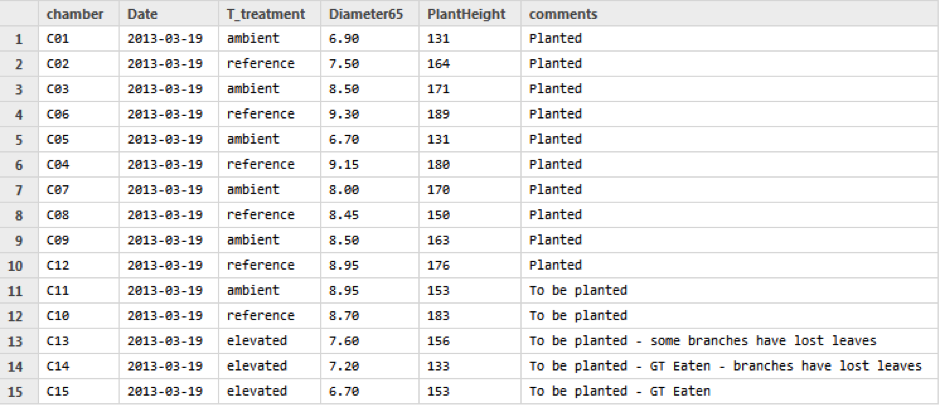
This is what a cleaned up version of tree measurements look like as a CSV file ( Note this file was generated by the ‘Whole Tree Chambers’ facility and includes only a subset of the full dataset).
Contact
Advice should be sought from the particular facility science/technical team and/or the HIE data manager if you need further guidance, any of the above is unclear, or if this is your first time uploading data to HIEv.